






“Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don’t think AI (Artificial Intelligence) will transform in the next several years.” – Andrew Ng

Alexa, don’t listen to my wife.
Cortana, where have I left my purse?
Siri, flip to the book I was reading last night.
These are commonplace statements that people like you and I make on an everyday basis. We have conversations with our digital assistants. We form a kinship with them; they become our virtual buddies, invisible but always ready with a quip to turn our frowns upside down. Our kids make friends with an Alexa or a Siri, and we don’t bat an eyelid. We rely on these absolutely wondrous inventions to keep us on track with our diets, so much so that we feel guilty for not following our self-set dietary and/or fitness goals.
The above-mentioned instances reinforce the ubiquity and prevalence of AI/ML in our daily lives. And it is not a revelation that this is a game-changing technology that has taken giant strides in the technology landscape in the recent past. With the technology becoming more accessible than ever before, nearly every product/solution that is pushed to the market has an aspect of it. In fact, it is harder to find a technology product that doesn’t have AI/ML in some form or the other, than to find one that does. With this as a reality, there will come a time in the near future, when products will easily pass the Turing Test, a feat that no machine has achieved – yet.
Other than its presence and prevalence in our everyday lives, AI/ML has seeped into many a field that doesn’t even work in technology directly. From transforming a ‘reactive repair technician’ to a ‘proactive problem solver,’ to utilizing it for affordable and accurate breast cancer screening for women, to leveraging the technology for computational biology, the pervasiveness of AI/ML is unparalleled. Global enterprises and start-ups alike are investing heavily in the technology, given its ubiquitous and plentiful applications in nearly every industry there is. And it’s not just the investments that are being pumped into it, but strategic initiatives that are being outlined to scale at a rapid pace.
By some estimates, the AI/ML spend is predicted to touch $400 Bn by 2020. Given this astronomical number, it makes it all the more important for organizations to scale their AI/ML initiatives and steer them towards success. However, there are numerous challenges that still hamper its scale.
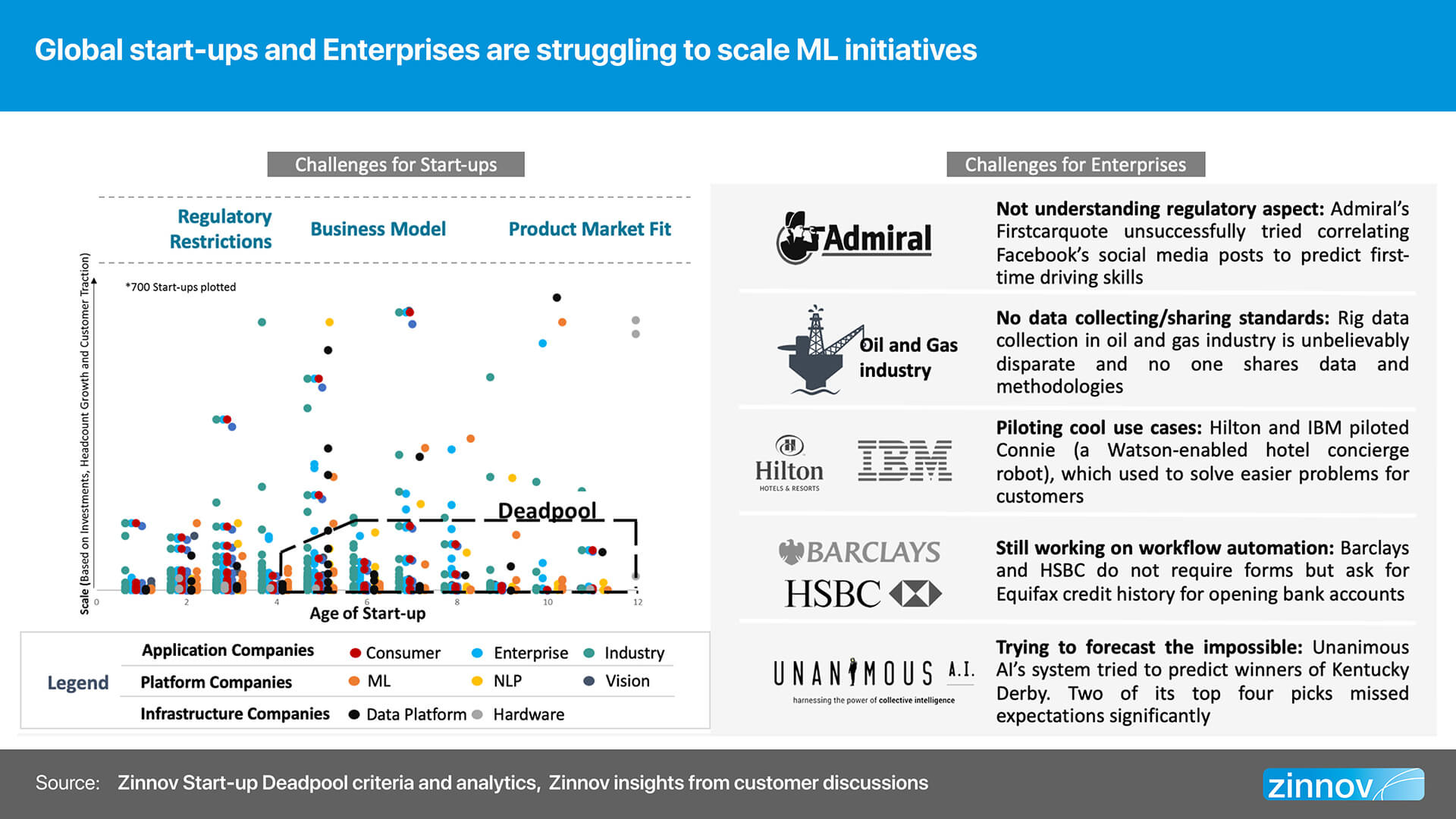
Who is to be held responsible if an autonomous car is involved in an accident – the owner of the vehicle or the manufacturer? Who should the AV protect – the passengers at any cost, or take a call as to how to minimize loss of life, even if it means endangering the passengers? Will an ML system fed biased data produce biased results? Who is to be held accountable for the misuse of intelligent AI/ML systems either through negligence or malice – the scientists who worked on them or the organization that hired them?
As the above scenarios exhibit, there are a lot of grey areas when it comes to AI/ML systems and the regulations therein. However, there isn’t an internationally recognized ethical and legal framework for the design, production, use, and governance of AL/ML and its numerous use cases. Setting the necessary frameworks up that are accepted internationally, will go a long way in giving a shot in the arm for organizations’ numerous AI/ML initiatives.
Admiral Insurance tried to model the eligibility of drivers’ insurance based on their Facebook posts. Not only did this violate regulatory aspects, but also resulted in privacy issues. Given the scale and magnitude of the Cambridge Analytica scandal that unfolded in the first half of 2018, this is a flawed business model for any organization – start-up or an enterprise – to pursue. If the fundamental premise on which the business model is built is in itself flawed, then the rationale on how any organization could create, deliver, and capture value doesn’t hold ground. This is merely one such example of a faulty business model, but similar instances can be seen across many ML initiatives of start-ups as well as enterprises, which hinder their scale.
Is there a strong demand for a product that relies heavily on AI/ML? Does the product/solution satisfy customer requirements? These questions need to be answered satisfactorily before embarking on developing a product for it to even make a mark in the market. One example where the start-up had a poor product/market fit was Unanimous AI. This ML-based start-up tried to predict the outcome of a completely random event like a Kentucky Derby, the world famous 2-minute horse race. Of course, the algorithm failed to predict the winner, because no one can predict an animal’s instincts, whether leveraging AI/ML or any other cutting-edge technology. Also, AI hasn’t yet reached a stage where it could successfully perform any intellectual task that a human being can.
Data is the new oil. And there is definitely no dearth of data that is collected the world over for various applications and use cases. However, the data collected is disparate and incongruous, with no standard methodologies employed, making it difficult to share and/or leverage it at all points in time.
The IoT space is a perfect example where two distinct bodies have come together to outline the safety protocols that could be employed across the industry. Google-backed Thread Group and Open Connectivity Foundation (OCF) will interoperate to advance the adoption of connected home products. In essence, this collaboration has allowed for a joint solution to emerge, that enables companies to develop solutions for the connected home more easily.
“There is far more opportunity than there is ability.” – Thomas Alva Edison
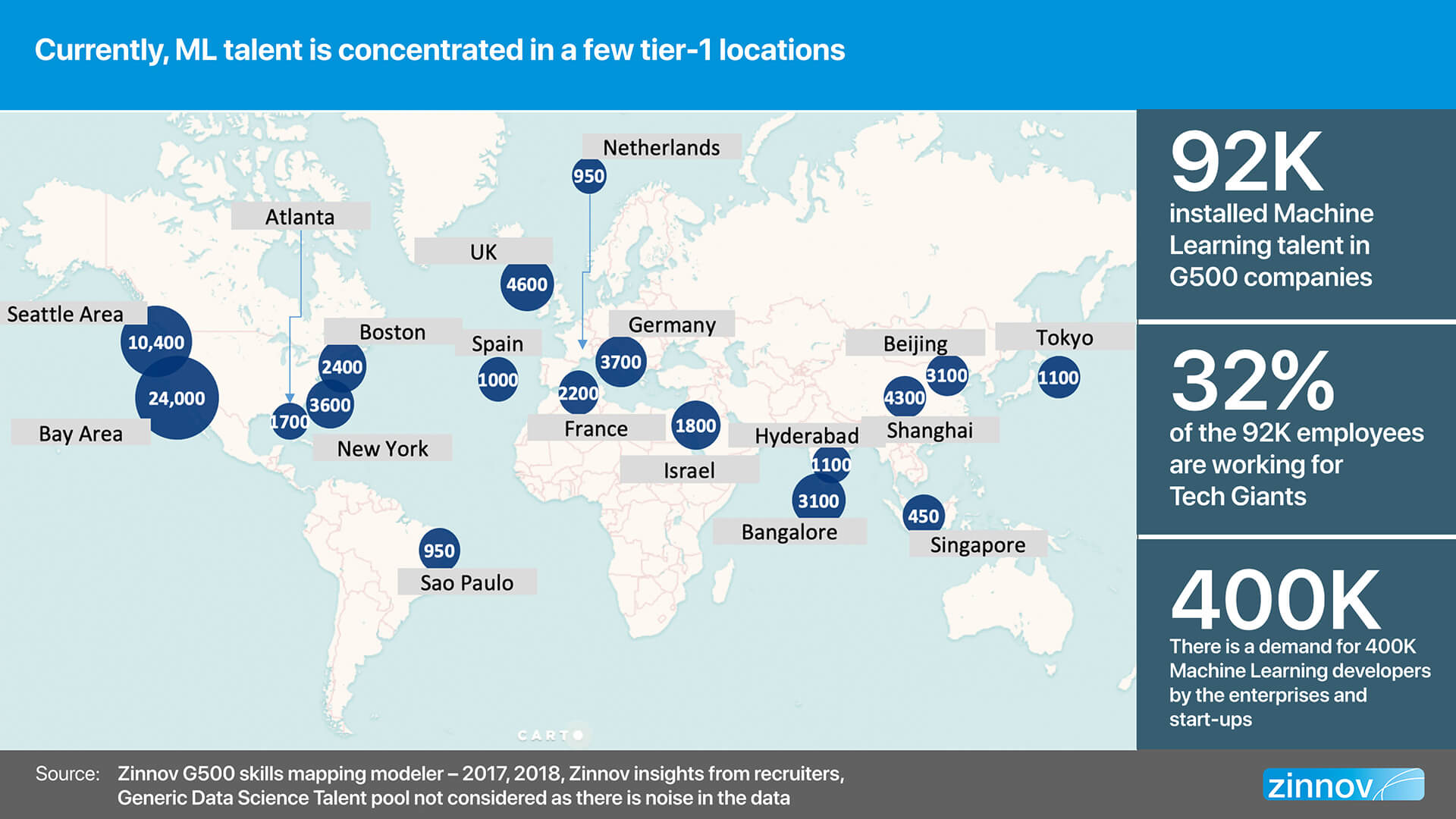
One of the major factors limiting scale is the inability to acquire and retain the right AI/ML talent. A big challenge is the skewed concentration of the niche ML talent. Most of the talent is concentrated in a few key locations, and resides within only a few large technology companies. The numbers speak for themselves – there is a total of about 92,000 installed Machine Learning talent across Global 500 companies, and a significant 32% of these people work for Top Tech Giants such as Google, Apple, Microsoft, etc. This talent gap is more pronounced as there is a demand for 400,000 ML developers by the enterprises and start-ups alike. Some of the key locations where this niche ML talent is housed include Seattle, Bay Area, Atlanta, Boston, New York, Germany, France, Israel, Bangalore, Shanghai, Beijing, Tokyo, to name a few.
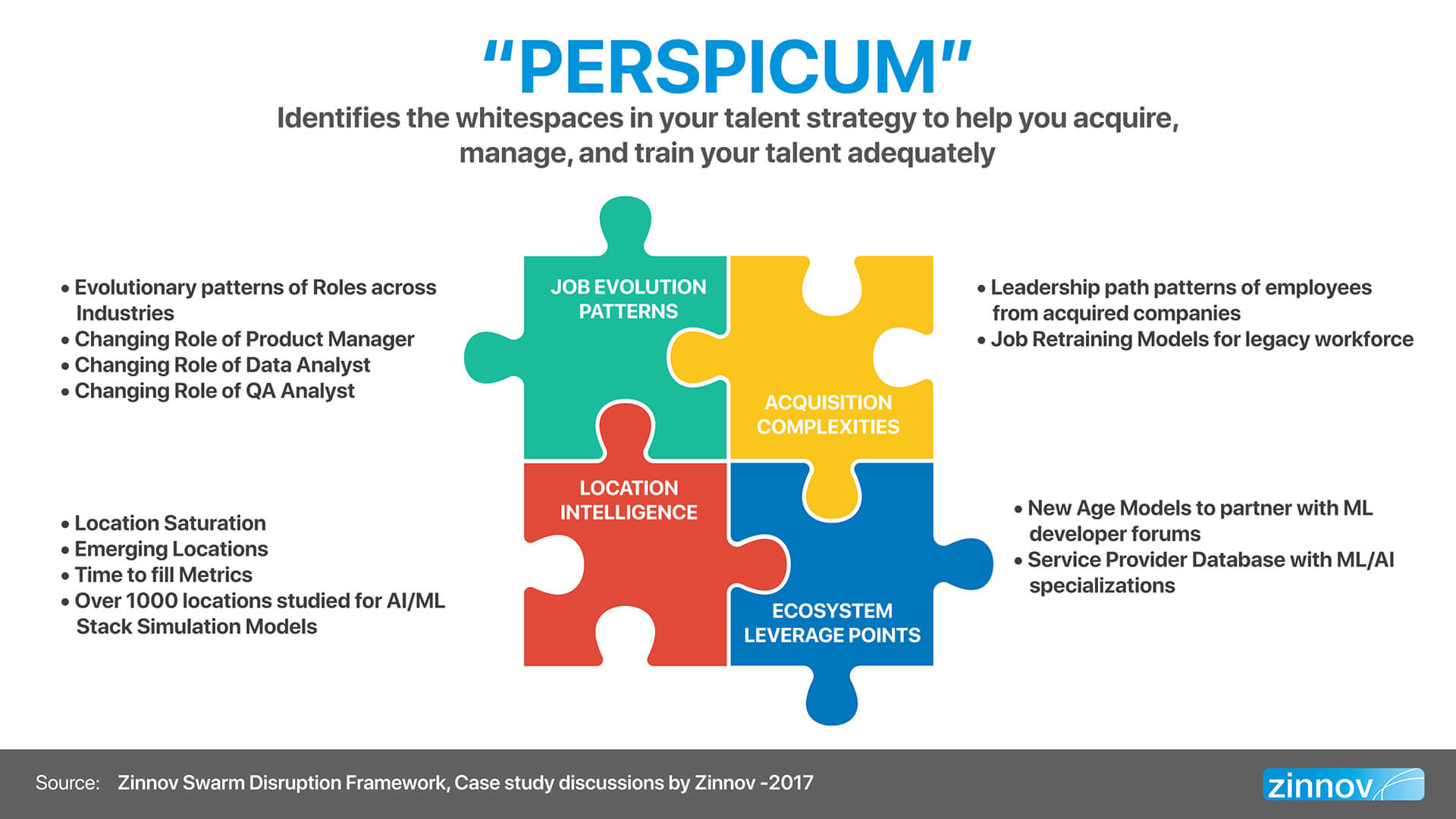
Zinnov has developed a framework called Perspicum, which equips enterprises with a blueprint on how to acquire and manage digital talent. In essence, this framework identifies the whitespaces in an organization’s talent strategy to help them acquire, manage, and train their talent adequately. This framework consists of 4 distinct elements –
Zinnov has identified over 250 job roles that are adjacent to ML across industries, which can potentially be honed into ML talent through structured training programs. All these identified job roles are one- or two-degrees closer to ML, providing hope that the deep talent chasm that exists between the supply and demand for this niche talent can be bridged in the near future.
Take the role of an actuary, as an example. Actuaries are reskilling themselves in programming languages and assembling components in the high computing environment. This has been made possible through online tools and programs provided by the likes of Kaggle and HackerEarth, along with specific enterprise training programs offered in organizations. Thus, today’s actuary is yesterday’s statistician and the day before yesterday’s operations research professional. That’s how the numerous job roles are evolving each day, bridging the gap between the need and the availability of ML talent.
Some of the other job roles that could potentially be honed into ML talent include biostatistician, purchasing agent, climatologist, economist, electrical engineer, chemist, cryptanalyst, computational biologist, financial analyst, to name a few. This only goes to show the impact that ML is having across industries, regardless of the vertical.
Acquiring smaller and/or competing companies comes with its own set of complexities, which need various leadership and change management programs to cope with. One of the complex aspects that acquiring companies need to be cognizant of is the change in leadership patterns of the employees from the acquired companies. Zinnov research points to a trend wherein approximately 20% of the fast-tracked leaders of an organization are not home-grown, but are lateral entries, especially through M&As. Another point of note that emerged from the research is that less than 5% of fast-tracked leaders are college entrepreneurs and/or dropouts.
An additional challenge that emerges when there is an acquisition is outlining job retraining models for the legacy workforce. This becomes an organization-wide exercise to bring the legacy workforce up to speed with the latest technological advancements in their specific domain as well as to keep them at par with the recently acquired talent.
There are key ecosystem players such as online platforms and Service Providers that enterprises can leverage to build AI/ML capabilities. ML developer platforms such as Kaggle, HackerEarth, etc., and Service Providers with the right capabilities can be honed into ML developers.
To put the latter into perspective, Zinnov tracks and rates about 300 global Engineering Service Providers with capabilities in ML space through its proprietary Zinnov Zones rating. This rating is an acknowledged standard across the technology space. There are approximately 5000 outsourcing decision-makers who actively employ Zinnov Zones for PES outsourcing-related decision-making. Additionally, around 400 companies consume the rating annually, to make enterprise-level decisions in the Service Provider landscape.
Leveraging online platforms is a quick way to develop several prototypes in a short period of time and a potential wellspring of talent that could be tapped, either through hiring and/or contracting. Take the case of a hackathon conducted by GE Healthcare in partnership with HackerEarth, to solve rural healthcare problems. The participants were asked to use ML to develop VCA (video content analytics) solution, contextual care protocol, and contextual training protocol. This yielded 31 prototypes, for a total prize money of INR 700K spent.

Zinnov has tracked and analyzed over 1000+ locations worldwide, and projected that there could be 130+ highly distributed ML talent hotbeds by 2030. The multi-pronged approach leveraged for the study also predicted that by 2030, as many as 37 countries will become home to approximately 1.3 million ML developers. It will be the much-needed shot in the arm for companies’ ML initiatives to become successful by solving for the talent gap. Multiple variables such as migration trends, university programs, smart cities’ growth, the presence of start-up accelerators, and various other socio-economic parameters were taken into consideration for this analysis.
Though multiple challenges exist that hinder scaling of organizations’ ML initiatives, the talent gap takes priority, for, without niche talent to work on the ML initiatives, the rest of them become sort of moot. And while the talent gap is not going to be bridged overnight, each organization needs to do its bit to shorten this chasm. Start-ups and enterprises alike need to explore the identified ML hotbeds in emerging locations. Further, they need to chalk out programs/initiatives to hone those job roles that are separated from ML talent by one- or two-degrees. Only when organizations work collectively and collaboratively to address this chasm between the demand and supply of niche ML talent, will they be able to scale their ML initiatives successfully.


